Hybrid RSF(Relative Score Fusion)와 DBSF(Distribution-Based Score Fusion)를 알아보자
제가 직접 작성한 것이 아닌 AutoRAG를 같이 만든 김병욱 연구원이 쓴 글입니다.
AutoRAG에는 4가지 Hybrid retrieval 모듈이 있다.
먼저 Hybrid Retrieval 모듈이 뭔지 간단하게 이해하고 넘어가보자.
🤔 Hybrid retrieval 모듈이란?
Hybrid, 말 그대로 2개 이상의 retrieval 모듈을 합쳐서 사용한다는 것이다.
Retrieval에서 가장 주로 사용하는 BM25와 Vector Search 결과를 Hybrid해서 사용 할 수 있다는 것이다.
BM25가 궁금하다면?
이렇게 해서 얻은 각각의 Retrieval 결과에 대해 Weight(가중치)를 줄 수 있다.
예를 들어 가중 치를 (BM25: 0.7, Vector: 0.3)으로 설정했다고 하자.
그럼 BM25 retrieval 결과에 0.7만큼의 가중치가, Vector Search retrieval 결과에 0.3만큼의 가중치가 곱해진 상태로 합산을 해 최종 retrieval 결과를 얻게 되는 것이다!
Hybrid Retrieval 모듈의 개념에 어느 정도 감이 잡혔는가?
아직 감이 잡히지 않았어도 괜찮다. 아래의 설명과 예제를 읽어보며 더 감을 잡아 보도록 하자.
이번 글에서는 Hybrid 중에서도 RSF와 DBSF에 대해서 설명해볼 것이다.
- Relative Score Fusion (Weaviate)
- Distribution-Based Score Fusion (Mazzecchi: blog post)
RSF는 Relative Score Fusion, DBSF는 Distribution Based Score Fusion의 약자이다.
눈치가 빠른 사람들은 벌써 RSF와 DBSF를 묶어서 설명하는 이유를 눈치 챘을 수도 있다.
바로 RSF와 DBSF는 모두 Score Fusion이라는 공통점이 있다! 두 모듈이 작동하는 방식이 거의 비슷하다는 뜻이다.
그렇다면 Score Fusion 알고리즘의 대략적인 흐름을 알아보자!
🔍 Score Fusion 알고리즘의 Flow
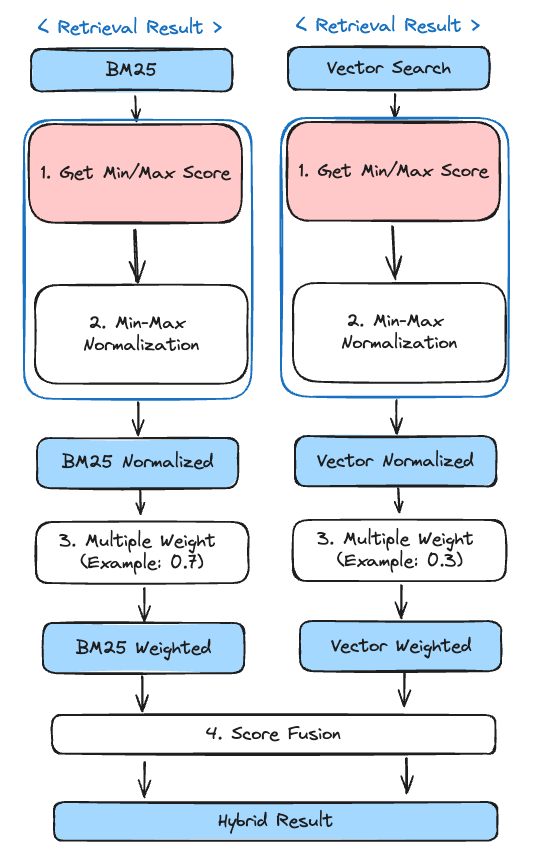
- Min, Max Score를 구한다
- Score list에 Min Max 정규화(Normalization)을 적용 (
Score list→Normalized Score list) - Normalized Score list 에 weight을 곱해줌 (
Normalized Score list→Weighted Score list) - Score Fusion 진행
다음과 같이 크게 4단계의 Flow로 진행이 된다.
RSF와 DBSF는 1번 Min-Max Score를 구하는 방법(그림에서 분홍색 색칠)만 다르고 2, 3, 4번 방법은 같다!
1. Min-Max Score 구하기 ⭐⭐⭐
그럼 가장 중요한 Min-Max Score를 어떻게 구하는 지 각각 알아보자 !
1–1. RSF
RSF는 Relative라는 용어에서 알 수 있듯 Min, Max Score는 상대적으로 결정된다.
상대적으로 결정된다는 건 무슨 뜻일까?
말 그대로 Score중 가장 큰 값이 Max Score, 가장 작은 값이 Min Score가 된다는 뜻이다.
예를 들어보자. 훨씬 간단하게 이해할 수 있다.
Score list: [1, 3, 5] 라고 하자.
그러면 Score list의 Max 값은 5, Min 값은 1이 된다.
1–2. DBSF
DBSF는 Distribution Based라는 용어에서부터 알 수 있듯, 분포를 이용해서 Min-Max Score를 구한다!
분포 중에서도 우리에게 가장 익숙한 정규 분포를 이용해준다.
정규 분포통계학에서 일반적으로 사용하는 "68–95–99.7 규칙" 또는 "3시그마 규칙"에 기반하여, Max Score = 평균 + 3 * 표준편차 Min Score = 평균 - 3 * 표준편차 로 구해준다!
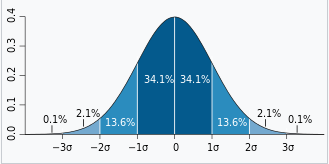
🤔 '3시그마 규칙'이란?
정규 분포를 따르는 데이터 세트에서:
- 약 68%의 데이터가 평균에서 ±1 표준 편차 이내에 존재한다.
- 약 95%의 데이터가 평균에서 ±2 표준 편차 이내에 존재한다.
- 약 99.7%의 데이터가 평균에서 ±3 표준 편차 이내에 존재한다.
따라서, 평균에서 3 * 표준 편차를 더하거나 빼면, 데이터의 거의 대부분(99.7%)이 이 범위 내에 포함된다는 것을 의미한다.
DBSF에서 Min-Max Score를 구하는 방법을 코드로 나타내면 다음과 같다! 더 자세하게 알고 싶은 분들을 위해 함께 첨부해본다 😉 (물론 표준 편차를 어떻게 구하는 지 까지 알지 못해도 모듈을 사용하는 데 전혀 지장은 없다!)
std_dev = (sum((x - mean_score) ** 2 for x in score_list) / len(score_list)) ** 0.5
min_score = mean_score - 3 * std_dev
max_score = mean_score + 3 * std_dev
이렇게 RSF, DBSF 각각의 방식으로 Min, Max Score를 구했다면, 이후의 Flow는 RSF와 DBSF 모두 동일하다!
2. Min-Max Normalization(최소-최대 정규화)
scaled_score = (score - min_score) / (max_score - min_score)
Min-Max Normalization은 값의 범위를 0~1로 조정하는 기법이다.
조정 후 최솟값은 0, 최댓값은 1이 된다.
예를 들어 [1, 3, 5] 라는 Score를 정규화하면, [0, 0.5, 1]이 되는 것이다.
3. weight 곱해주기
우리는 Hybrid retrieval module을 알아보고 있기 때문에 각각의 Normalized Score에 Weight를 곱해주어야 한다.
[0, 0.25, 1] Score와 [0, 0.5, 1] Score가 있다고 해보자.
Weight가 0.7, 0.3이라면 각각의 Score 값에 0.7과 0.3을 곱해주기만 하면 된다!
4. Score Fusion
Fusion의 뜻은 융합, 융해, 연합, 합병 등이 있다.
대충 뭔가를 합친다는 뜻이다.
Score Fusion 말 그대로 우리가 얻은 2개의 Weighted Score를 합쳐주는 과정이다!
- id: [ id_1, id_2, id_3], Score: [0.1, 0.2, 0.7]
- Id: [ id_2, id_3, id_4], Score: [ 0.3, 0.8, 0.2]
다음과 같은 2 개의 결과가 있다고 하자
id_1과 id_4는 1개만, id_2, id_3는 2개가 있다.
그러면 다음 두 결과를 다음과 같이 합쳐준다.
id_1 : 0.1
id_2 : 0.2 + 0.3 = 0.5
id_3 : 0.7 + 0.8 = 1.5
id_4 : 0.2
예시에서는 top_k가 3인 상황을 가정하고 있으므로, 점수 순서대로 상위 3개를 골라보면,
Id: [id_3, id_2, id_4], Score: [1.5, 0.5, 0.2] 가 된다.
이렇게 2개의 Score Fusion Module인 Hybrid RSF와 Hybrid DBSF에 대해 알아보았다!
더 읽어보기
AutoRAG - RAG 자동 최적화 & 평가 툴 => 링크
RAG에서 BM25가 더 좋을 수도 있습니다. => 링크
한국어 문서에서 BM25 사용 시 꼭 확인해야 할 것 => 링크
RAG Retrieval 메트릭 이해하기 (영문) => 링크